
Saviez-vous que Typescript n'a pas pour but d'être mathématiquement correct ? C'est à la suite de ces constats que j'ai suivi l'évolution de Rust pour le web. Il existe de nombreuses alternatives à JS, que ce soit par transpilation ou par le wasm: ReasonML, Haskell, Kotlin, Smalltalk, etc. Alors pourquoi Rust ?
Le typage
Si on fait du Typescript, c'est pour les types évidemment ! Et en Rust, les types sont plutôt bien pensés et mathématiquement corrects. En quoi est-ce important ? Voici un exemple qui nous éclaire sur le fait que nous ne pouvons croire les interfaces TS :
//test on https://www.typescriptlang.org/play?ts=5.3.2
// source of example : https://weeklyjs.io/typescript/2022/03/11/why-you-cannot-trust-typescript-interfaces.html
interface User { userId: string; }
interface Address { street: string; }
interface IAddressRepository {
getAddress(user: User | string): Address ;
}
class AddressRepository implements IAddressRepository {
getAddress(user: User) { console.log(user.userId.length); return { street: "string"}; };
}
const repository: IAddressRepository = new AddressRepository();
repository.getAddress('someUserID');
Sur le code ci-dessus, nous n’observons aucune erreur à la compilation malgré la différence de typage entre la signature de getAddress dans l'interface et dans la classe. En revanche, à l'exécution, vous aurez l'erreur TypeError: user.userId is undefined.
Pour l'explication courte : contrairement aux fonctions, les paramètres des méthodes sont bivariants. On peut passer un sous type ou un type dérivé. Pour l'explication longue, je vous encourage à lire Why you cannot trust typescript interfaces
En particulier, les enums sont plus intuitifs (pas de problèmes liés à la transpilation) et rien ne vaut un petit exemple :
En Typescript, changer une enum provoque de potentielles erreurs :
enum Size {
S,
M,
L
}
console.log(Size.S) // 0
console.log(Size.M) // 1
console.log(Size.L) // 2
S'il y a ajout de nouvelles valeurs, il devient impératif de les mettre à la fin, sous peine d'avoir ce résultat :
enum Size {
XS,
S,
M,
L
}
console.log(Size.S) // 1
console.log(Size.M) // 2
console.log(Size.L) // 3
Dans l'exécution même du programme, ce changement d'index est anodin. Mais si ces index sont stockés à l'extérieur, les valeurs deviendront incohérentes. Les énumérations en Rust fonctionnent ainsi :
#[derive(Debug)] // <- cette macro permet d'avoir un affichage par défaut
enum Size {
S,
M,
L
}
fn main() {
println!("{:#?}", Size::S); // S
println!("{:#?}", Size::M); // M
println!("{:#?}", Size::L); // L
}
Donc les valeurs ne changeront pas, même si on ajoute la valeur XS en premier. Si vous voulez retrouver des valeurs numéraires, il vous faudra faire une fonction de transformation.
De plus, la culture de la vérification des types est tellement ancrée dans la communauté que Sqlx dispose de la vérification des requêtes SQL à la compilation (vérification syntaxique et du typage par rapport au modèle de votre base).
Le compilateur
L'écosystème TS s'est suffisamment complexifié pour venir ajouter une couche de compilation (ou de transpilation selon les outils). Si bien qu'utiliser un langage compilé n'a plus un réel impact sur les temps de développement.
De plus, le compilateur Rust est explicite sur ses erreurs et fournit des pistes sur les solutions les plus courantes directement dans la console. Le code d'erreur fourni permet d'avoir plus d'explications sur la doc en ligne. Jugez par vous même :
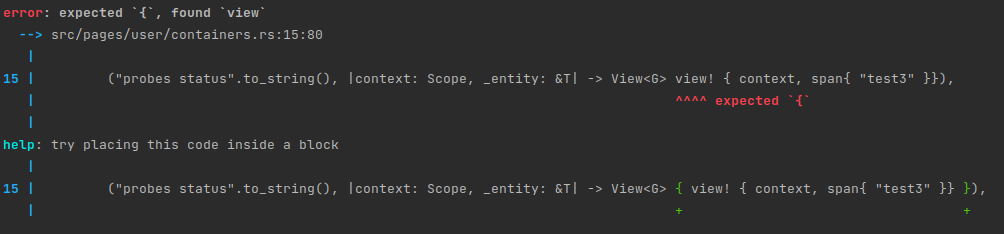
Il utilise ainsi les types pour soulever de potentielles erreurs qui auraient été détectées au runtime en TS. Prenons encore les enums en exemple. Le code suivant est valide en TS et peut partir en prod :
enum Size {
S,
M,
L
}
function fireAndForget(param: string) {
console.log(param)
}
function display(v: Size) {
switch (v) {
case Size.M:
fireAndForget("moyen");
break
case Size.L:
fireAndForget("grand");
break
}
}
Tentons la même chose en Rust :
#[derive(Debug)]
enum Size {
S,
M,
L
}
fn fire_and_forget(param: &str) {
println!("{}",param)
}
fn display(v: Size) {
match v {
Size::M => {fire_and_forget("moyen");}
Size::L => {fire_and_forget("grand");}
};
}
fn main() {
display( Size::L);
}
Nous obtenons l'erreur suivante :
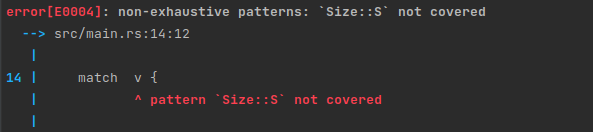
Il devient donc impossible d'oublier de couvrir de cas sur un match à un des quinze endroits où l'enum est utilisée dans le programme.
La mutabilité
Rust propose une mutabilité explicite. Une variable ne pourra être changée que si nous la déclarons mutable. Et contrairement aux const de TS, une variable non mutable ne pourra pas voir ses propriétés changées.
Cela évite de chercher si une variable a été modifiée dans une fonction et facilite le debug en diminuant le champs des possibles. Imaginons que nous passons et modifions une variable à travers un programme, pour afficher le résultat à la fin. Voici un code pour illustrer cela :
fn function_one(_variable: &usize) {
// some read operations and call to other functions
}
fn function_two(_variable: &usize) {
// some read operations and call to other functions
}
fn function_three(_variable: &mut usize) {
// some read operations and call to other functions
_variable = _variable*3;
fn function_four(_variable: &usize) {
// some read operations and call to other functions
}
fn main() {
let mut variable = 15;
function_one(&variable);
function_two(&variable);
function_three(&mut variable);
function_four(&variable);
prinln!("{} should be equal 30", variable); //print 45 should be equal 30
}
Mais horreur, malheur, nous n'obtenons pas le bon affichage à la fin ! 30 n'est pas égal à 45. En Typescript, nous devrions vérifier chaque appel de fonction pour vérifier qu'il n'y ait pas de modification de variable. En Rust, on constate que seul l'appel de la fonction function_three a une référence mutable. Le problème vient forcement de cette fonction et on constate que nous triplons la valeur au lieu de la doubler.
Mais cela facilite aussi la concurrence. En effet, nous ne pouvons avoir qu'un pointeur mutable simultanément pour chaque variable. Ce qui élimine le besoin de jongler avec des mutex tant que nos fonctions ne partagent pas une même variable mutable.
La gestion des dépendances
Un projet est défini par un fichier (Cargo.toml) similaire à un package.json. On y définit des meta tels que le nom du projet, des espaces de travail et des dépendances. Les espaces de travail permettent de créer facilement des monorepo un peu comme avec Nx ou Lerna. Vous trouverez plus d'informations sur les monorepo dans cet article
Haut et bas niveau
Rust est un langage bas niveau, immuable par défaut, permettant d'aller chercher de la performance, de paralléliser facilement des opérations et ce, sans garbage collector. Si votre service est soumis à des latences indésirables dues à des garbages collects, Rust est une solution éprouvée par de grands comptes comme Discord.
Mais cette performance s'accompagne de concepts à apprendre, dont certains sont assez complexes :
- les macros, code qui s'exécute à la compilation pour générer du code. Complexe à écrire mais très simple d'utilisation.
- le borrow checker, qui est chargé de libérer la mémoire à chaque fin de bloc de code.
- les lifetimes, plus difficile à maîtriser, ce concept intervient quand on veut retourner un pointeur à la fin d'un bloc de code. Il faut rajouter des indications sur la fonction et les paramètres pour assurer que le pointeur ne concerne pas une valeur qui sera supprimée à la fin du bloc. A moins de chercher à réduire la complexité en temps et en espace sur des détails d'implémentations, nous pouvons ignorer les lifetimes et faire des copies comme dans d'autres langages.
- la concurrence, avec les concepts d'asynchrone bloquant, non bloquant, de synchrone bloquant et synchrone non bloquant. Ces soucis sont cachés par la nature événementielle de JS alors qu'en Rust, ce sont les librairies qui vont cacher cette difficulté. Par exemple, la librairie de serveur Axum est multithreadée avec juste l'utilisation d'une macro pour régler le nombre de threads
#[tokio::main(worker_threads = 1)]
Le concept d'async/await a une syntaxe familière :
async fn get_probe_usecase(pool: &PgPool, data: GetProbeData) -> Option<Probe> {
DataProbes::get(pool, data.probe_id).await
}
Les débutants Rust pourront copier les objets plutôt que d'utiliser les pointeurs mais dans l'absolu, utiliser des librairies cachant cette complexité sera plus performant. Dans cet article sur leptos, vous pourrez constater une abstraction similaire à svelte. Je vous propose aussi un aperçu sur la sérialisation et désérialisation :
// import de la macro Serialize de la librarie serde
use serde::{Serialize};
//application de la macro qui va générer automatiquement le code serialisation
#[derive(Serialize)]
pub struct Probe {
pub id: i32,
pub name: String,
pub unit: String,
pub probe_type: String,
pub min: f64,
pub max: f64,
pub container_id: i32,
}
Toute la complexité citée plus haut est cachée par la macro Serialize. Passer par une macro rallonge un peu la compilation par rapport à une implémentation directe dans le fichier, mais cela n’entraîne pas de surcoût à l'exécution qui serait dû à la réflectivité.
Pour exécuter la sérialisation, il faudra rajouter la lib correspondante au format désiré. Par exemple pour du json :
use serde_json::json;
let probe = Probe::new(3,"sonde".to_string(), "°C".to_string(), "température".to_string(), 7, 25, 1)
json!(probe);
Conclusion
Cet écosystème bouge rapidement et semble très prometteur. Des entreprises telles qu'Amazon, Google ou Discord s'intéressent à Rust, investissant aussi bien pour le monde de l'embarqué que pour le web. Des PME s'en servent sur des cartes embarquées pour servir leurs interfaces via le web. Et c'est un langage apprécié des développeurs.
Pour finir, un excellent terrain pour ce genre de transition est d'utiliser Rust pour le code critique dans node JS grâce à librairie Neon ou dans un environnement micro front. Si vous découvrez le concept, Didier Girard en a fait un article de présentation sur le micro front








{kind=link}